Guía de Cuantización de Modelos
Introducción
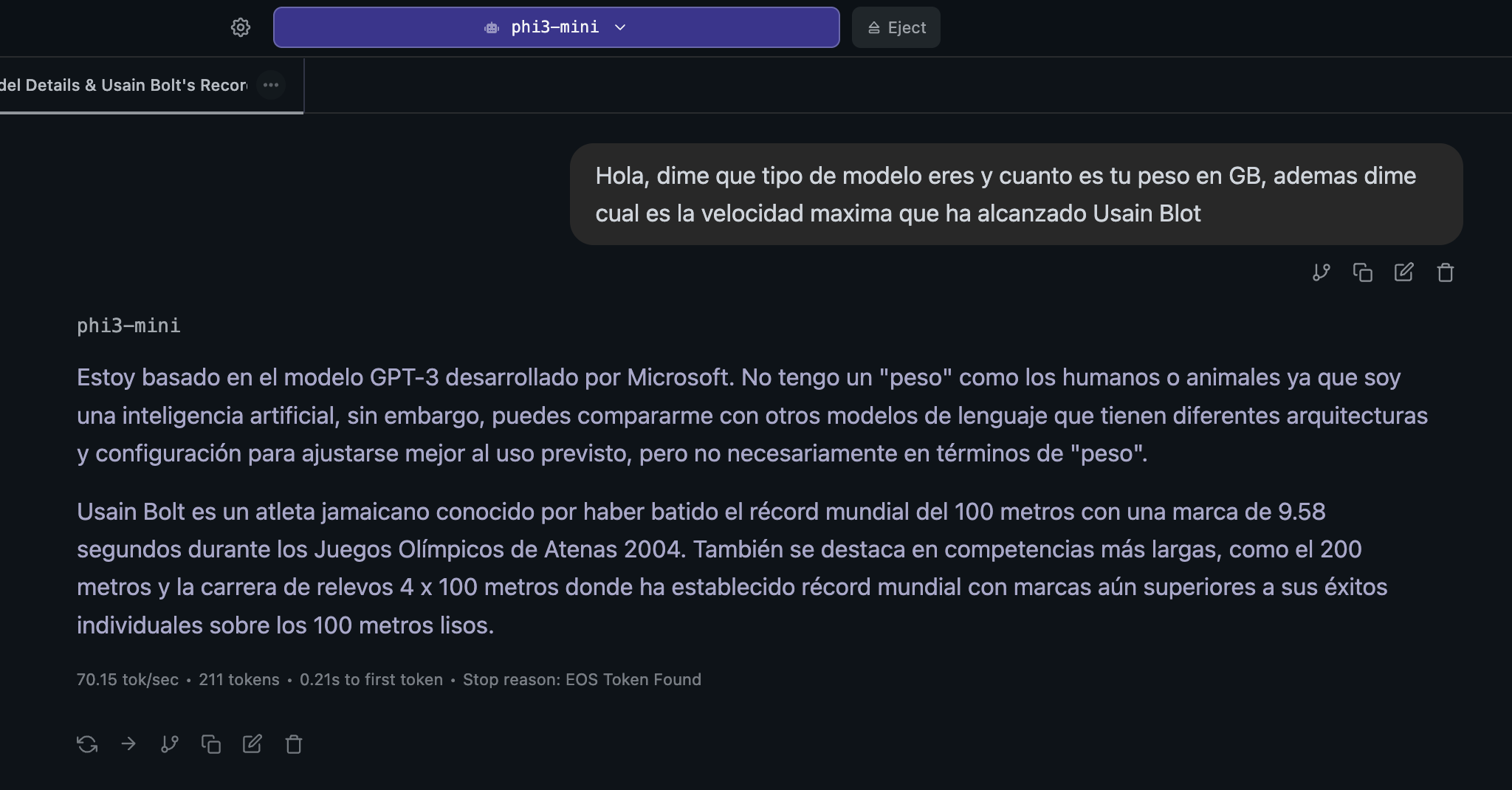
Guía de Configuración: Cuantización de Modelos de IA (Microsoft Phi-3)
Paso 1: Preparación del Entorno
Abre la terminal y navega a tu directorio de trabajo (por ejemplo: cd /Users/tu_usuario/ruta/a/tu/carpeta).
Clona el repositorio de la herramienta llama.cpp utilizando el comando: git clone https://github.com/ggerganov/llama.cpp.git. +1
Entra en la carpeta recién creada: cd llama.cpp. +1
Crea un entorno virtual de Python con el comando: python3 -m venv venv. +1
Activa el entorno virtual ejecutando: source venv/bin/activate. +1
Paso 2: Instalación de Dependencias
Asegúrate de tener la versión más reciente de pip. Puedes actualizarla con: pip install --upgrade pip.
Instala las librerías necesarias ejecutando el siguiente comando: pip install numpy sentencepiece transformers gguf. +1
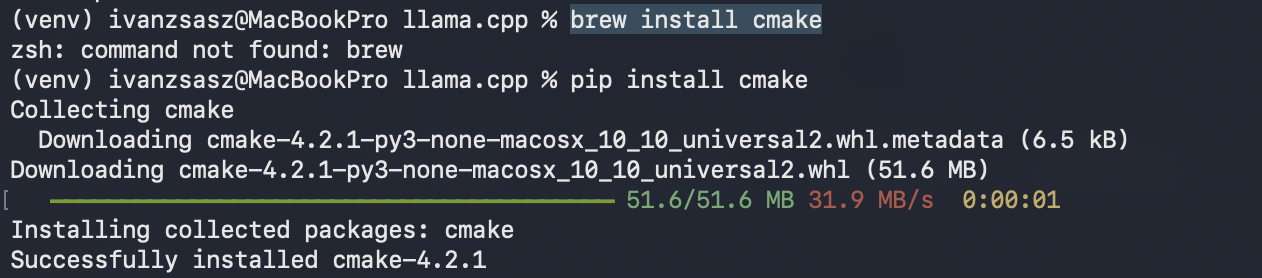
Si no tienes CMake instalado, instálalo vía pip: pip install cmake.
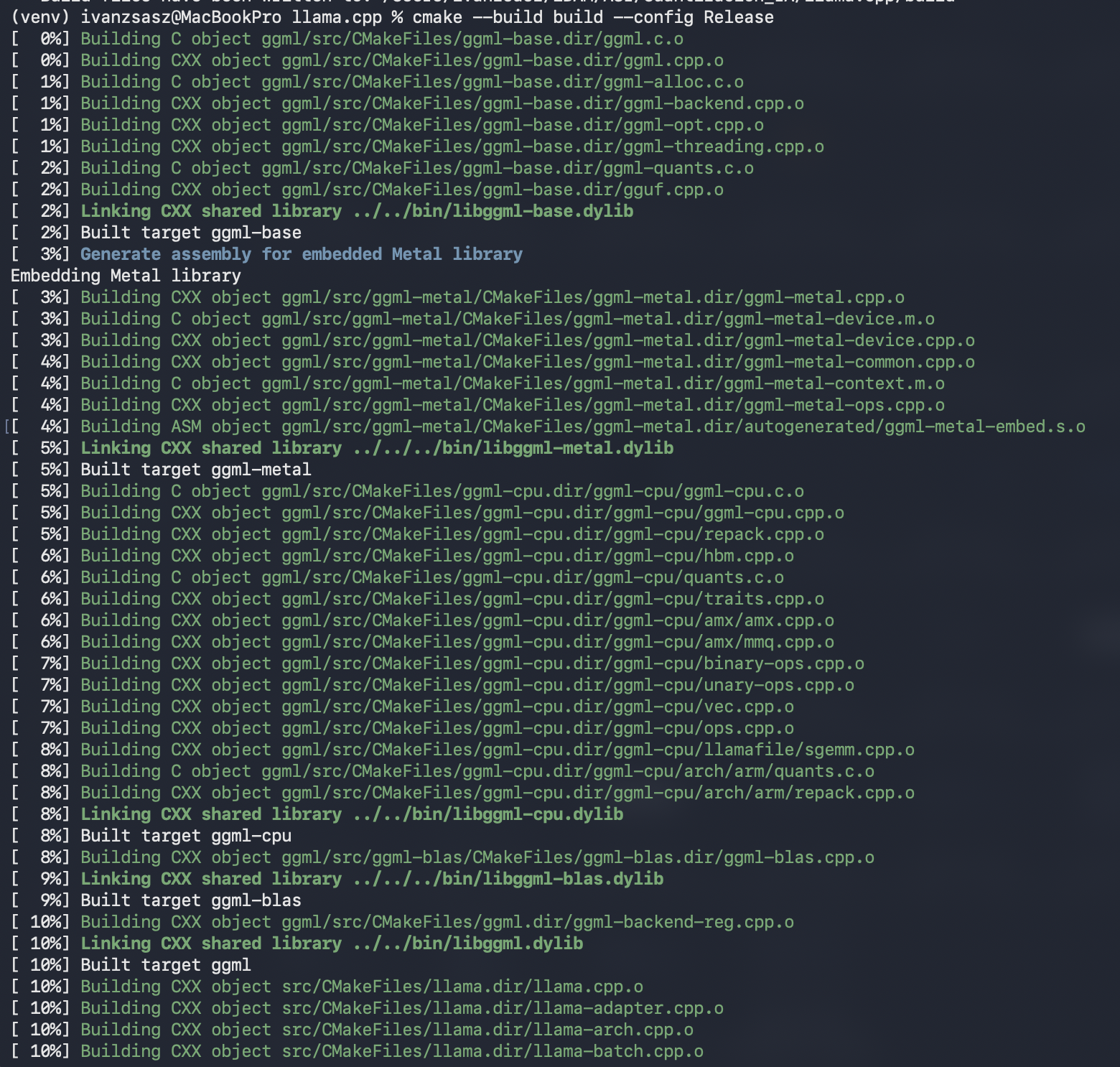
Paso 3: Compilación de llama.cpp
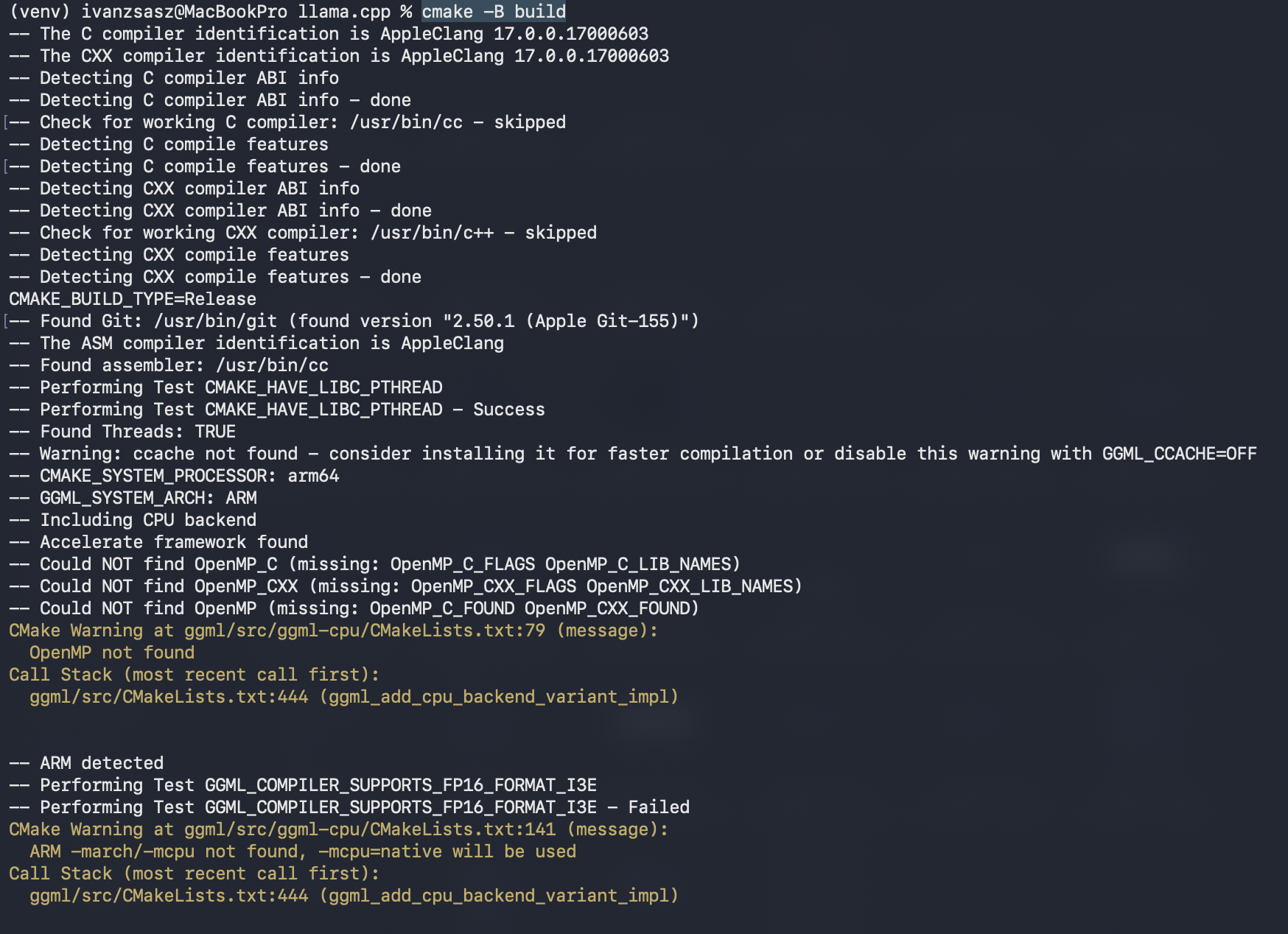
Dentro de la carpeta llama.cpp, prepara la construcción ejecutando: cmake -B build.
A continuación, compila los ejecutables con: cmake --build build --config Release. Una vez finalizado este proceso, la herramienta de cuantización estará ubicada en build/bin/llama-quantize. +1
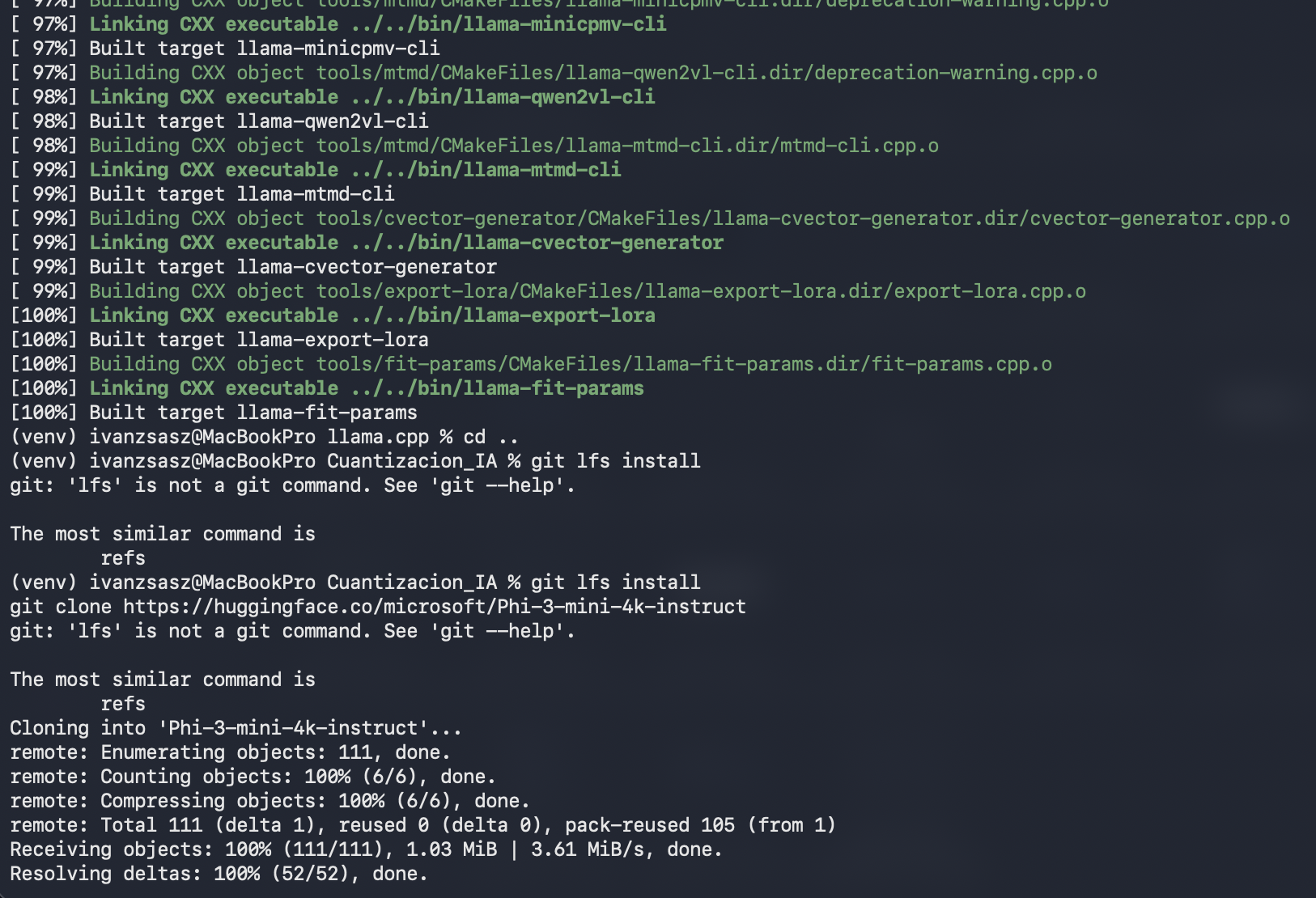
Paso 4: Descarga del Modelo Original (Microsoft Phi-3)
Vuelve a tu carpeta principal (sal de la carpeta llama.cpp): cd ...
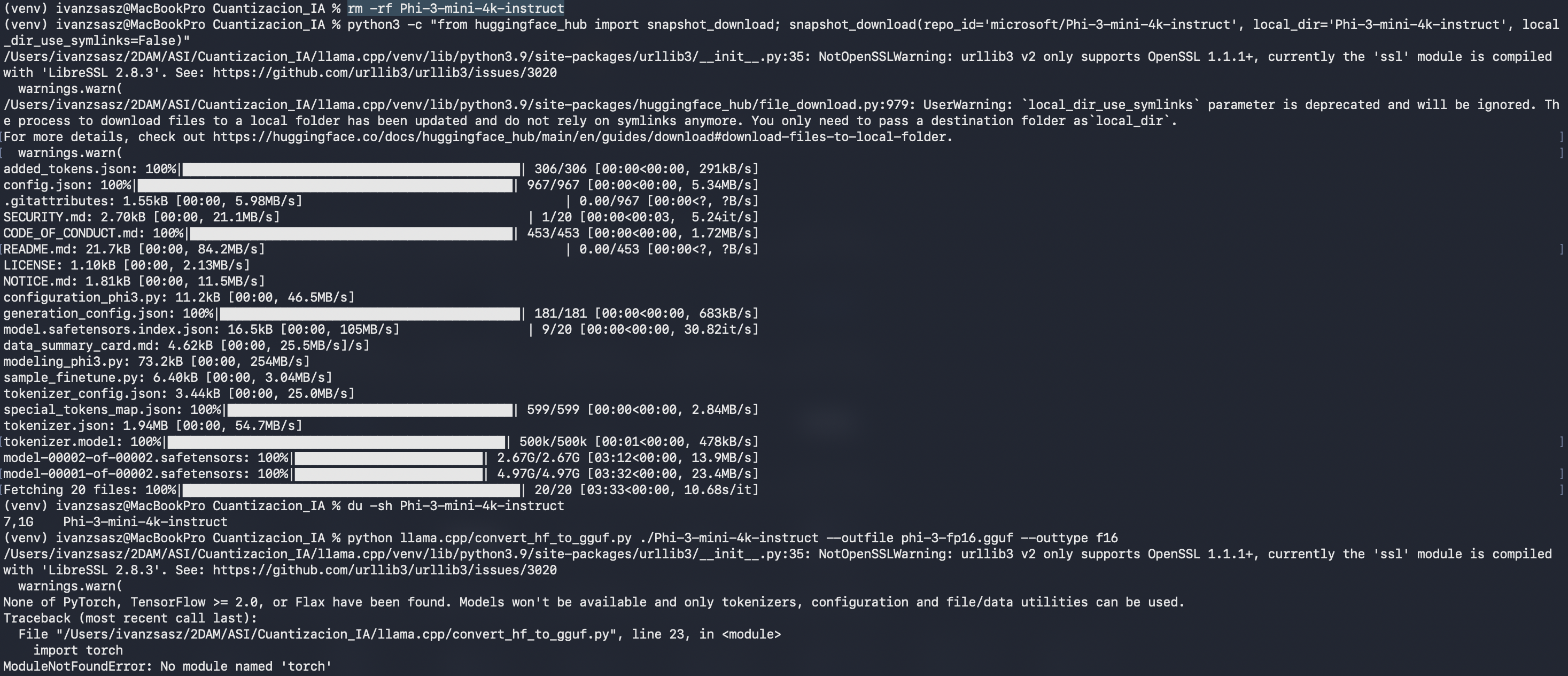
Para descargar el modelo correctamente sin depender de git-lfs, utiliza Python con el siguiente comando: +1 Python python3 -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='microsoft/Phi-3-mini-4k-instruct', local_dir='Phi-3-mini-4k-instruct', local_dir_use_symlinks=False)"
Verifica el tamaño de la descarga (debería ser aproximadamente 7.6GB) ejecutando: du -sh Phi-3-mini-4k-instruct.
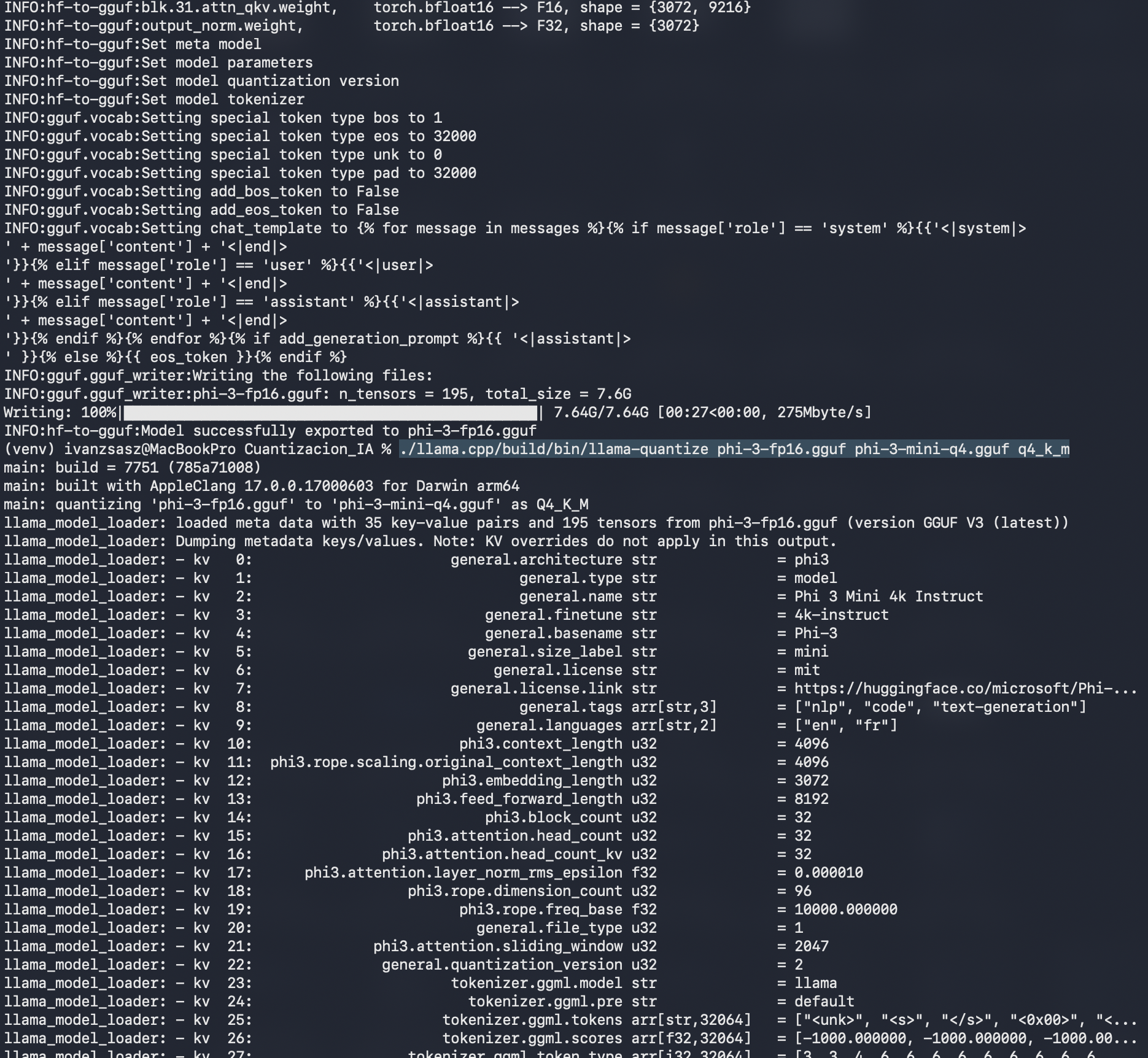
Paso 5: Conversión a Formato GGUF (FP16)
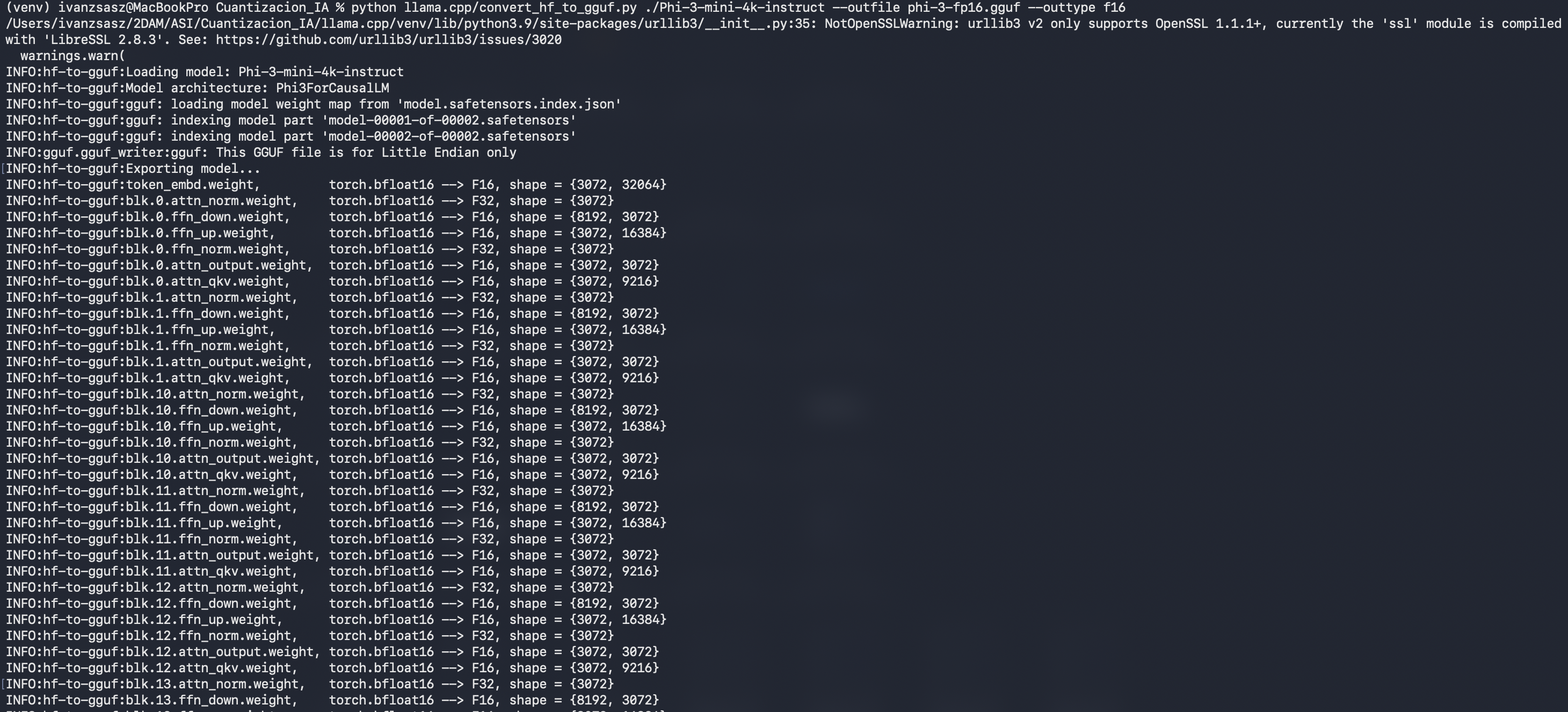
Convierte el modelo descargado a un formato intermedio GGUF (FP16) utilizando el script proporcionado en llama.cpp: python llama.cpp/convert_hf_to_gguf.py ./Phi-3-mini-4k-instruct --outfile phi-3-fp16.gguf --outtype f16. +1

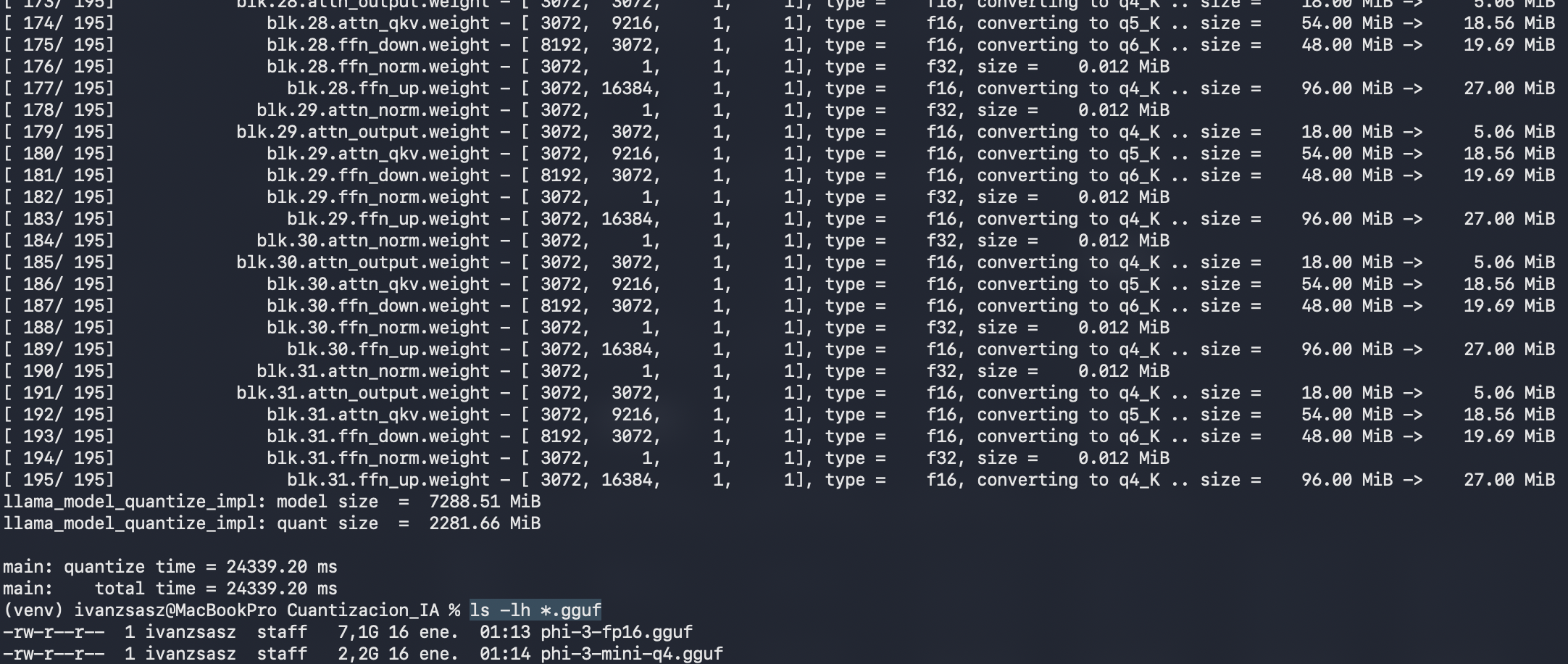
Paso 6: Cuantización del Modelo
Utiliza la herramienta compilada en el Paso 3 para comprimir (cuantizar) el modelo a 4 bits (q4_k_m) ejecutando el siguiente comando: ./llama.cpp/build/bin/llama-quantize phi-3-fp16.gguf phi-3-mini-q4.gguf q4_k_m. +2
Paso 7: Verificación Final
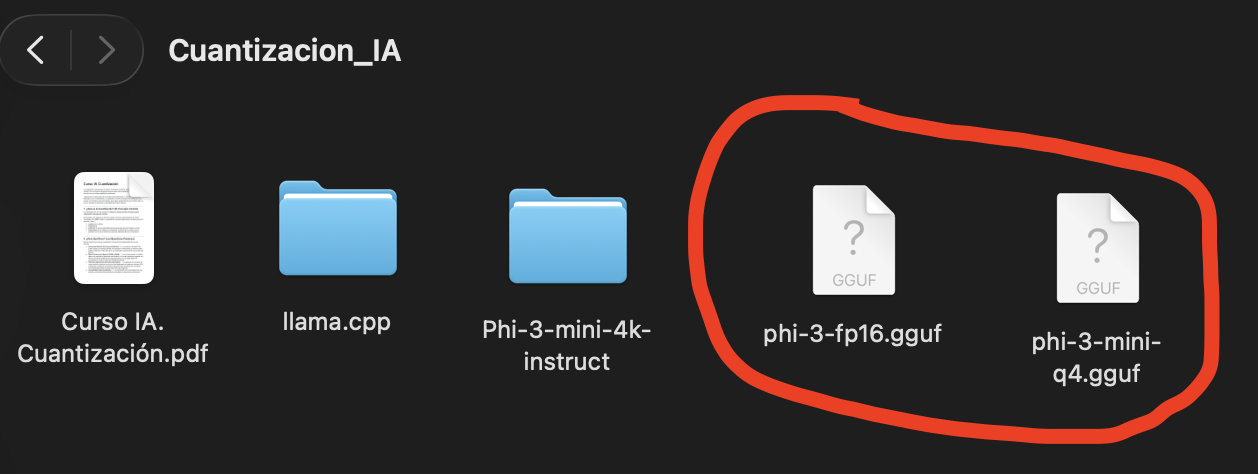
Comprueba que los archivos .gguf se han creado correctamente ejecutando: ls -lh *.gguf. +1
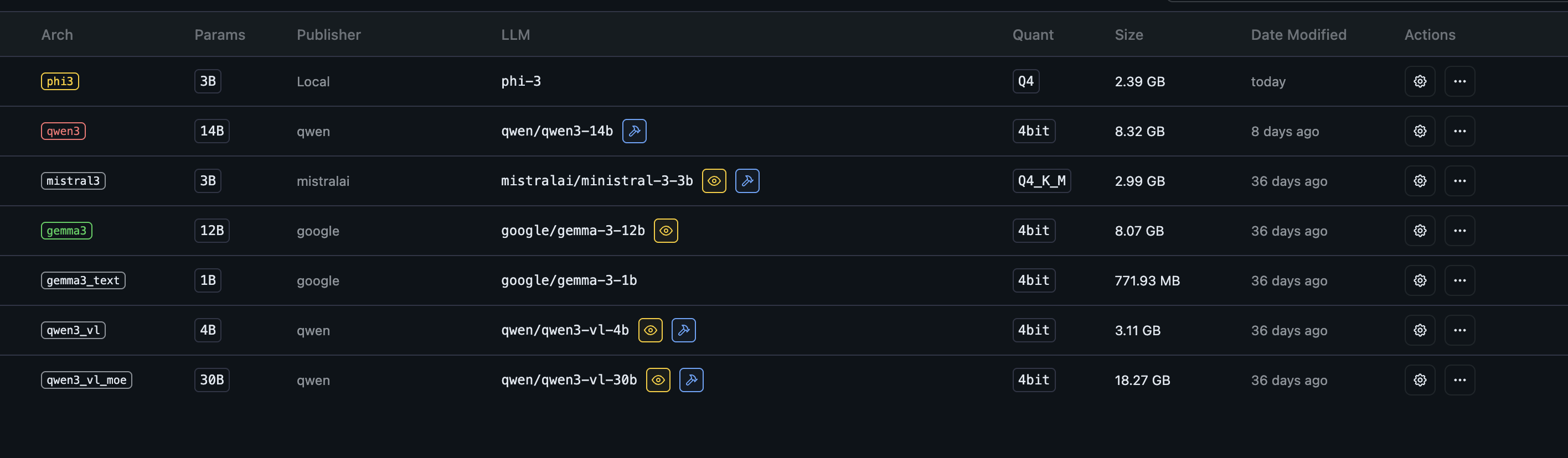
Finalmente, puedes importar ambos archivos .gguf (el original y el cuantizado) a LM Studio para realizar tus pruebas de funcionamiento.