Manual: Fine-Tuning con LoRA
Introducción
Memoria de Práctica: Fine-Tuning de LLMs con LoRA en Apple Silicon

1. Introducción y Objetivos
El objetivo de esta práctica es realizar un proceso de Fine-Tuning (ajuste fino) sobre un Modelo de Lenguaje Grande (LLM) pre-entrenado. Según la documentación teórica de la asignatura, buscamos especializar un modelo generalista para convertirlo en un asistente experto en formalidad, capaz de responder siempre utilizando el tratamiento de "usted" y manteniendo un tono profesional.
Para esta implementación, hemos adaptado el flujo de trabajo estándar (generalmente diseñado para GPUs NVIDIA y Linux) para ejecutarlo nativamente en un MacBook Pro con chip M1/M2/M3 (Apple Silicon), utilizando la librería MLX de Apple, que permite un uso eficiente de la memoria unificada.
2. Preparación del Entorno en Mac (Apple Silicon)
A diferencia del entorno con CUDA (NVIDIA), en Mac necesitamos preparar un entorno aislado que utilice la potencia de la GPU de Apple (Metal).
Pasos Realizados:
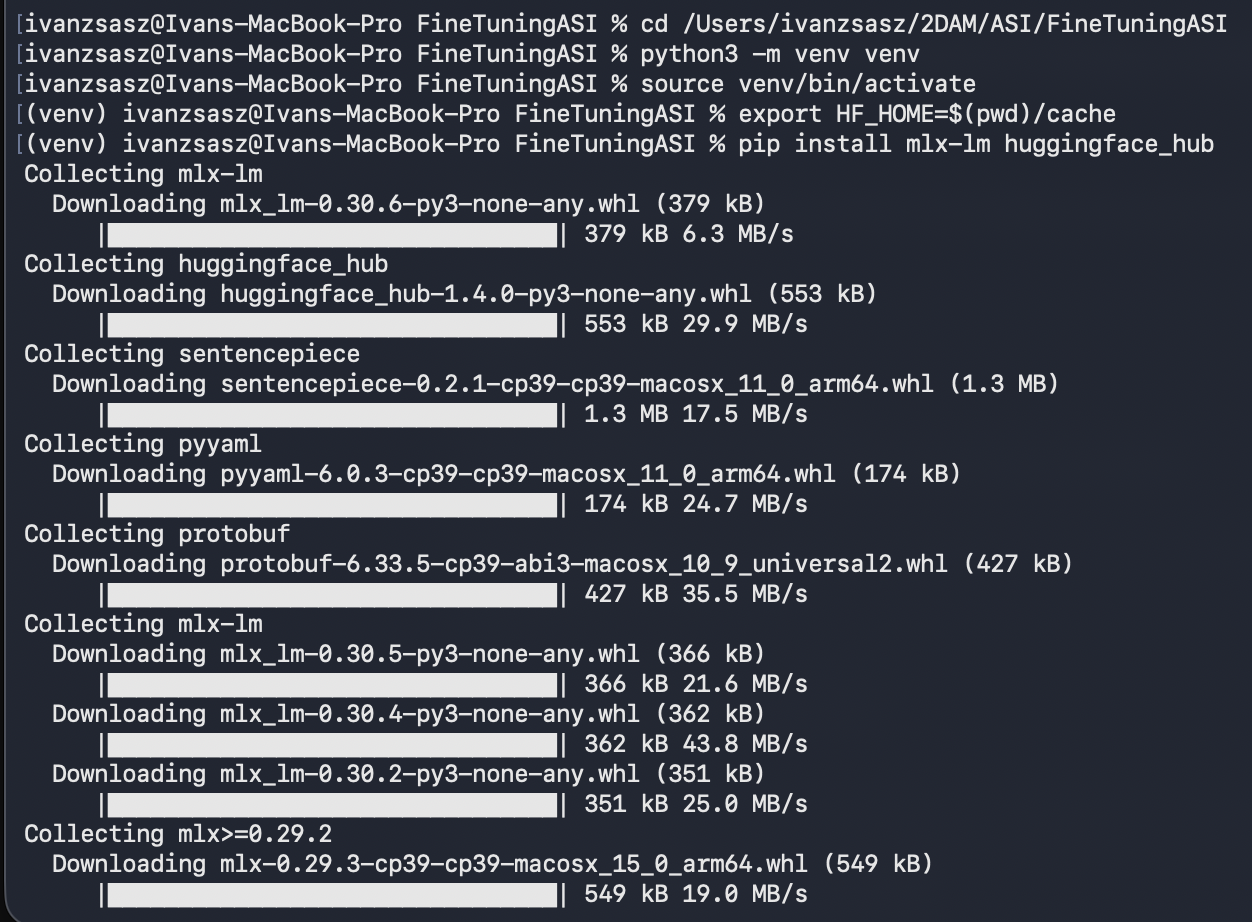
1. Creación del directorio de trabajo: Lo primero es generar una estructura limpia para evitar conflictos con otros proyectos.
2. Aislamiento del entorno (Virtual Environment): Creamos un entorno virtual (venv) para instalar las librerías específicas de esta práctica sin contaminar la instalación global de Python en el Mac.
3. Gestión eficiente del almacenamiento: Los LLMs son pesados (varios GB). Configuramos la variable HF_HOME para forzar a que los modelos descargados de Hugging Face se guarden dentro de nuestra carpeta de proyecto. Esto facilita la limpieza posterior: al borrar la carpeta del proyecto, se borra también la caché de modelos.
4. Instalación de librerías nativas: Instalamos mlx-lm, la librería optimizada por Apple para el entrenamiento de modelos de lenguaje en sus chips, junto con las herramientas de Hugging Face.
Evidencia del proceso: Aquí se muestra la instalación de las dependencias y la descarga de los paquetes necesarios.

3. Creación y Estructuración del Dataset
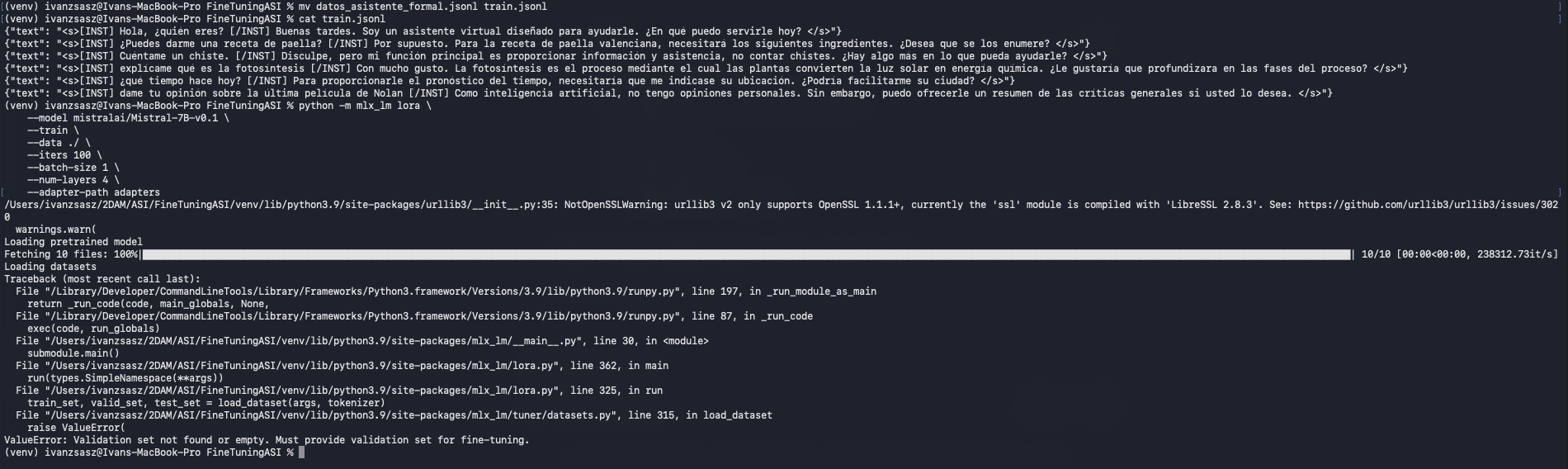
La calidad del dataset es el factor más crítico ("Garbage in, garbage out"). Hemos creado un archivo JSONL (JSON Lines) siguiendo el formato de instrucción de Mistral ([INST] ... [/INST] ... ).
Contenido del archivo train.jsonl: Hemos definido pares de instrucción y respuesta ideal. El modelo aprenderá que ante preguntas comunes, debe responder con una estructura gramatical formal y educada.
Ejemplo de entrada:
Comandos utilizados:
# (Tras guardar el contenido)
4. Entrenamiento del Modelo (Fine-Tuning con LoRA)
En lugar de reentrenar todo el modelo (Full Fine-Tuning), que requeriría recursos industriales, utilizamos LoRA (Low-Rank Adaptation). Esta técnica congela el modelo base y solo entrena capas pequeñas de adaptadores, siendo mucho más rápido y eficiente.
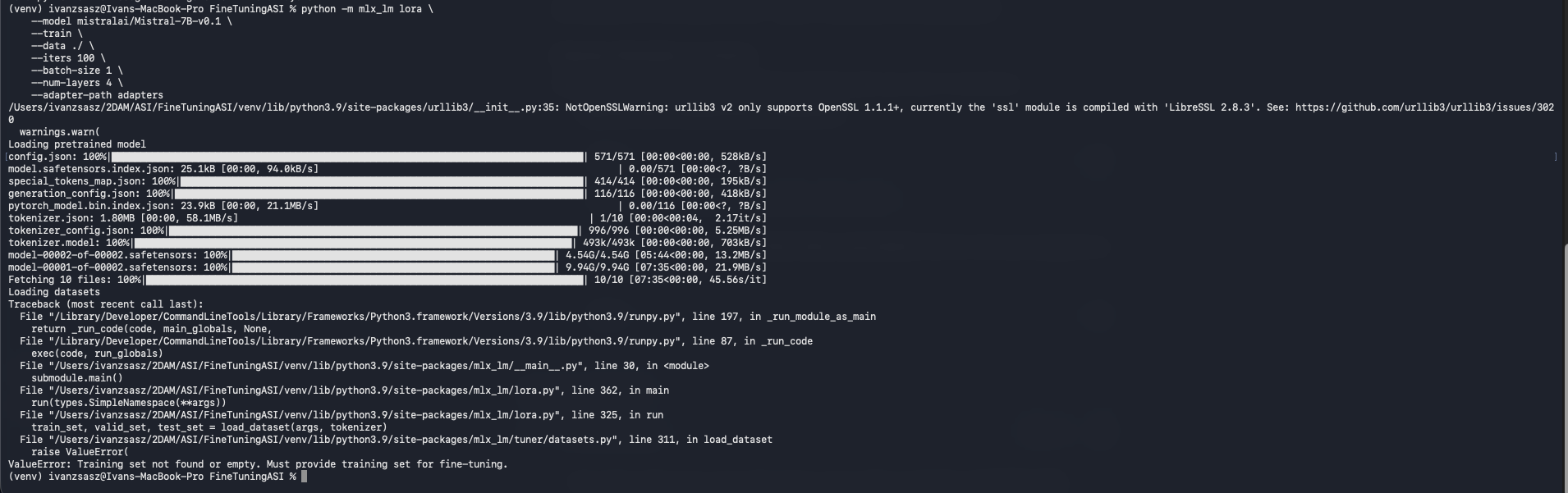
Primer intento (Error de configuración):
Inicialmente, intentamos usar el argumento --lora-layers, pero la versión actualizada de mlx ha cambiado la nomenclatura.
Segundo intento (Error de Dataset):
Al corregir el comando, surgió un error indicando que no encontraba el set de entrenamiento. Esto se debió a que la herramienta busca por defecto archivos con nombres estándar (train.jsonl, valid.jsonl). Solución: Renombramos nuestro archivo y creamos copias para validación y test, satisfaciendo los requisitos de la librería.
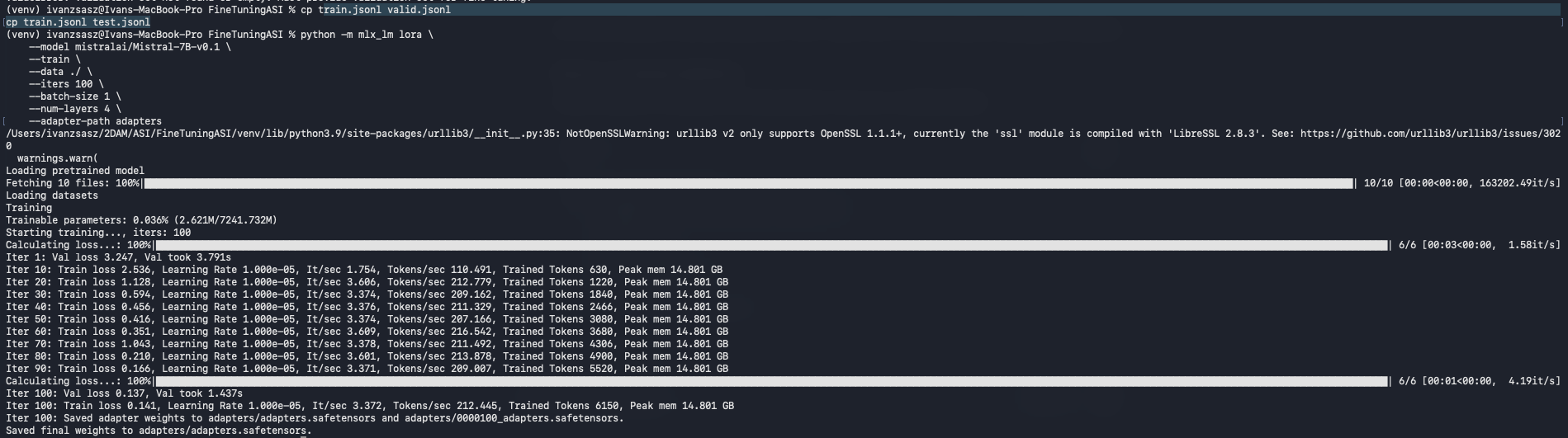
Ejecución Exitosa:
Finalmente, lanzamos el entrenamiento con los parámetros ajustados para el hardware local:
Model: mistralai/Mistral-7B-v0.1
Iteraciones: 100 (Suficientes para una prueba de concepto).
Batch size: 1 (Para minimizar el uso de VRAM).
Capas (LoRA): 4.
--model mistralai/Mistral-7B-v0.1 \
--train \
--data ./ \
--iters 100 \
--batch-size 1 \
--num-layers 4 \
--adapter-path adapters


5. Fusión y Conversión del Modelo (GGUF)
Una vez obtenidos los "adaptadores" (los archivos ligeros con el aprendizaje nuevo), debemos fusionarlos con el cerebro original (Mistral) y convertir el resultado a un formato ejecutable estándar (GGUF) para usarlo en aplicaciones como LM Studio.
A. Fusión (Fuse)
Unimos los pesos base con nuestros adaptadores LoRA:
--model mistralai/Mistral-7B-v0.1 \
--adapter-path adapters \
--save-path modelo_fusionado
B. Preparación de llama.cpp
Clonamos la herramienta estándar de conversión. Tuvimos que resolver dependencias faltantes manualmente, ya que el archivo requirements.txt pedía versiones incompatibles con nuestra versión de Python. Solución: Instalación manual de paquetes esenciales (numpy, sentencepiece, gguf, protobuf, torch).
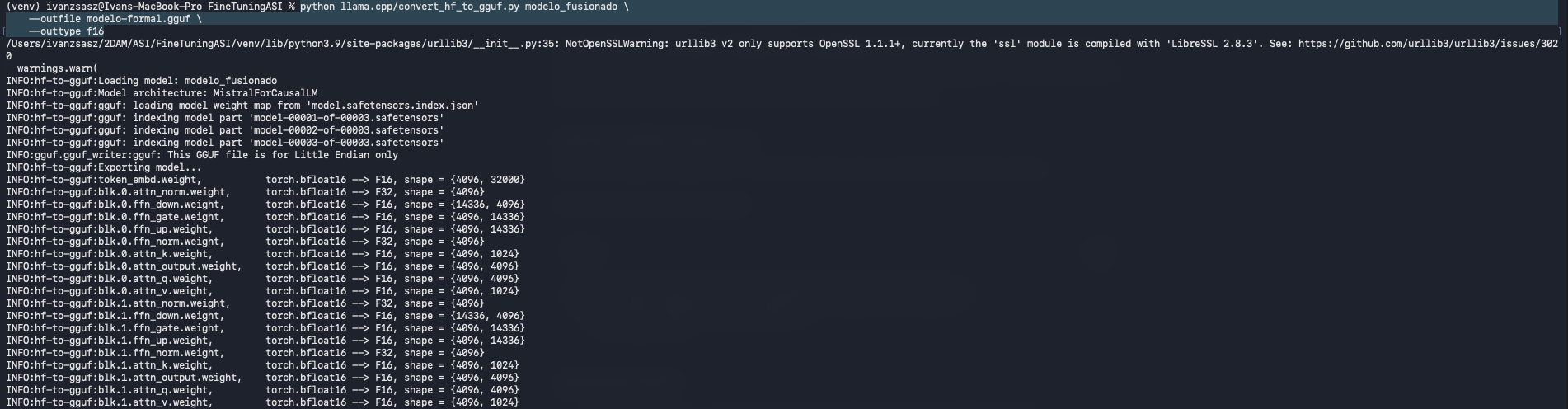
C. Conversión a GGUF
Aquí encontramos un obstáculo técnico importante. El PDF original sugería una cuantización directa a q4_k_m. Sin embargo, el script de conversión actual no soporta esa cuantización "al vuelo". Solución Técnica: Optamos por convertir el modelo a precisión media (f16). Aunque el archivo resultante es más pesado (aprox. 14GB vs 4GB), conserva una mayor calidad y precisión en las respuestas, lo cual es ideal para demostraciones.
Comando final exitoso:
--outfile modelo-formal.gguf \
--outtype f16

6. Pruebas y Resultados
El archivo final modelo-formal.gguf se importó en LM Studio.
Prueba de Inferencia: Al preguntar "Hola, ¿quién eres?", el modelo respondió con la frase exacta entrenada: "Buenas tardes. Soy un asistente virtual diseñado para ayudarle...".
Esto confirma que los pesos del modelo fueron modificados exitosamente mediante LoRA, logrando que el LLM abandone su comportamiento genérico y adopte la personalidad definida en el dataset.

7. Conclusiones y Aprendizaje
La realización de esta práctica ha permitido consolidar varios conceptos clave del Fine-Tuning:
Viabilidad en Apple Silicon: Se ha demostrado que es posible realizar entrenamientos de IA complejos en hardware de consumo (MacBook Pro) usando librerías optimizadas como MLX, sin necesidad de servidores con GPUs NVIDIA industriales.
Importancia del Dataset: Los errores encontrados durante el proceso (como la falta de archivos de validación) refuerzan la teoría de que la preparación y estructuración de los datos es la parte más sensible del proceso.
Gestión de Dependencias: La resolución de conflictos de versiones (pip, torch, matplotlib) es una habilidad esencial en la ingeniería de IA, ya que las herramientas evolucionan muy rápido.
Flexibilidad de LoRA: Hemos comprobado cómo LoRA permite modificar el comportamiento de un modelo gigante (7B de parámetros) entrenando solo una fracción mínima de parámetros, haciendo el proceso rápido y eficiente.