Documentación: Entrenamiento y Despliegue
Introducción
Documentación de Proyecto: Entrenamiento y Despliegue de LLM Local (Cervantes-GPT)
Fecha: 5 de Febrero, 2026 Hardware: NVIDIA GeForce RTX 4070 (12GB VRAM) Sistema Operativo: Windows 11 + WSL2 (Ubuntu 24.04) Objetivo: Entrenar un Modelo de Lenguaje (LLM) desde cero con el texto de "El Quijote", convertirlo a formato estándar GGUF y ejecutarlo en una interfaz de usuario final (LM Studio).
1. Configuración del Entorno de Alto Rendimiento
Para aprovechar la aceleración por hardware de la RTX 4070, se descartó el uso de Windows nativo en favor del Subsistema de Linux para Windows (WSL2), debido a su mejor gestión de memoria y compatibilidad con herramientas de IA.
1.1 Instalación de WSL2 y Dependencias
Comando: wsl --install (PowerShell Admin).
Distribución: Ubuntu.
Preparación: Actualización de paquetes (apt update && upgrade).
1.2 Gestión de Entornos Python
Al intentar instalar librerías, encontramos el error externally-managed-environment (propio de versiones modernas de Ubuntu).
Solución: Uso de entornos virtuales (venv) para aislar el proyecto.
Bash
1.3 Instalación de PyTorch con CUDA
Se instaló la versión específica compatible con los drivers de NVIDIA para habilitar la GPU:
Bash
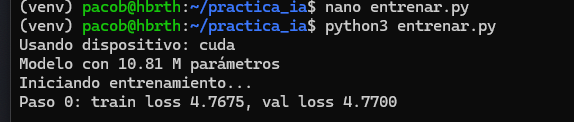
Verificación: torch.cuda.is_available() devolvió True detectando la RTX 4070.



2. Fase 1: Entrenamiento Educativo (NanoGPT)
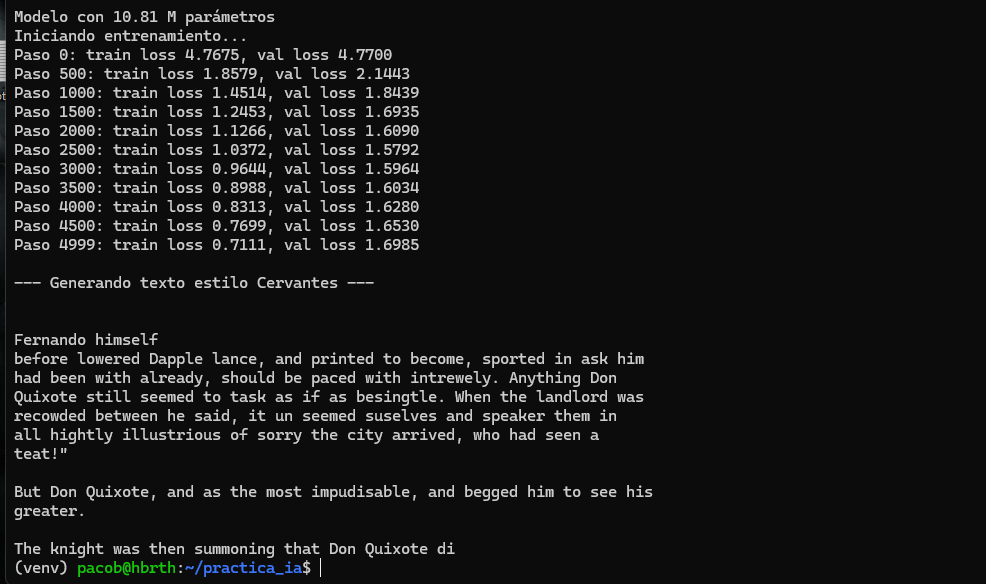
Se realizó un primer entrenamiento utilizando una arquitectura Transformer "artesanal" (basada en NanoGPT) para comprender los conceptos de Loss, Tokens y Atención.
Script: entrenar.py.
Configuración: Batch size aumentado a 64 y contexto de 256 tokens para aprovechar la VRAM de la 4070.
Resultado: El modelo aprendió a estructurar palabras y frases estilo castellano antiguo.
Limitación: Al ser una arquitectura personalizada, no era compatible con herramientas de conversión estándar (llama.cpp). No se podía exportar a GGUF.
3. Fase 2: Entrenamiento para Producción (GPT-2 + HuggingFace)
Para lograr la exportación a LM Studio, se migró a una arquitectura estándar (GPT-2) utilizando la librería transformers.
3.1 Retos Técnicos y Soluciones
Durante la creación del script entrenar_gpt2.py, surgieron varios errores críticos debido a actualizaciones recientes de las librerías:
Error ImportError: cannot import name 'TextDataset':
Causa: La función fue eliminada en versiones recientes de transformers.
Solución: Se programó una clase personalizada MiDatasetDeTexto(Dataset) que tokeniza el texto y lo divide en bloques manualmente.
Error TrainingArguments... overwrite_output_dir:
Causa: Cambio en la API de HuggingFace.
Solución: Se implementó limpieza manual de carpetas usando la librería shutil de Python antes de iniciar el entrenamiento.
Warning de Longitud de Tokens:
Solución: Se ajustó el tokenizer.model_max_length para evitar advertencias al procesar el texto completo del Quijote.
3.2 Ejecución Exitosa
El modelo se entrenó durante 3 épocas. La RTX 4070 completó el proceso en minutos. El modelo resultante se guardó en formato HuggingFace (pytorch_model.bin).

4. Fase 3: Compilación y Conversión (Llama.cpp)
Para convertir el modelo a GGUF (formato optimizado para inferencia local), se utilizó la herramienta llama.cpp.
4.1 Compilación de Herramientas C++
Se instalaron build-essential, git y cmake.
Incidencia: El comando make falló porque el proyecto migró a cmake.
Solución: Se utilizó el nuevo sistema de construcción:
Bash
4.2 Resolución de Conflictos de Python
El archivo requirements.txt de llama.cpp generaba conflictos con torchaudio.
Solución: Instalación quirúrgica de solo lo necesario: pip install gguf protobuf.
4.3 Generación del GGUF
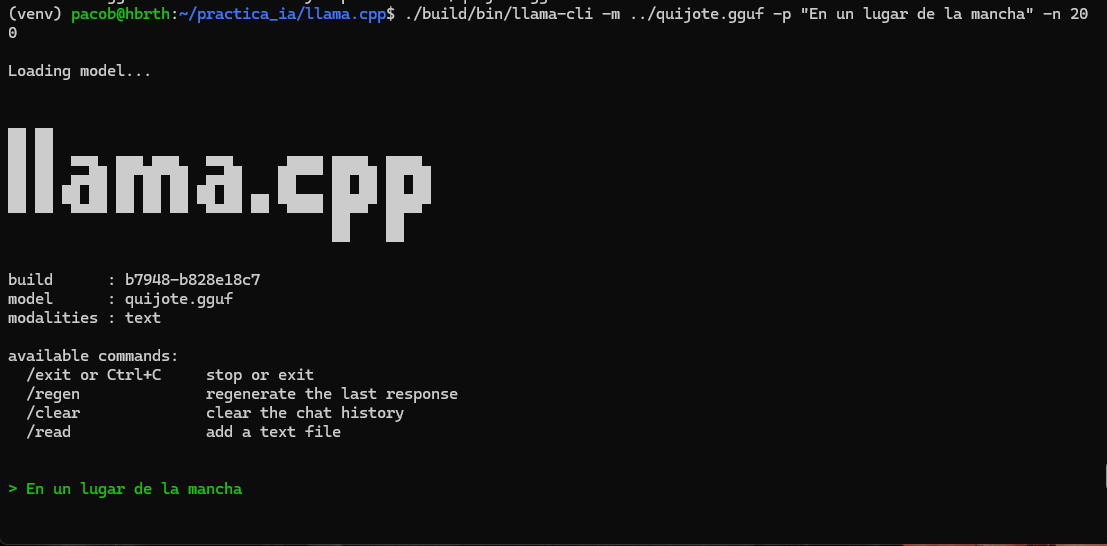
Se ejecutó el script de conversión sobre el modelo entrenado en la Fase 2:
Bash
Resultado: Archivo quijote.gguf generado correctamente.

5. Fase 4: Despliegue en LM Studio (Windows)
El paso final consistió en mover el archivo de Linux a Windows y ejecutarlo.
5.1 Estructura de Directorios
LM Studio no reconocía el modelo inicialmente.
Solución: Se tuvo que cumplir la estructura estricta de carpetas: C:\Users\Usuario\.cache\lm-studio\models\Paco\Quijote\quijote.gguf
5.2 Bloqueo de Seguridad de Windows
Al intentar cargar el modelo, apareció el error: "Una directiva de Control de aplicaciones bloqueó este archivo".
Diagnóstico: Smart App Control o Windows Defender bloquearon las librerías no firmadas del motor de inferencia.
Soluciones aplicadas:
Ejecutar LM Studio como Administrador.
Añadir la carpeta .lmstudio a exclusiones de Windows Defender.
(Opcional) Desactivar Smart App Control.
6. Resultado Final
El modelo Cervantes-GPT es funcional.
Capacidad: Autocompletado de texto (Text Completion).
Rendimiento: Generación instantánea gracias a la ejecución local.
Estilo: Imita el vocabulario y gramática del Siglo de Oro español.
Conclusión del proyecto: Se ha logrado dominar el ciclo completo de MLOps (Machine Learning Operations) a pequeña escala: Datos -> Entrenamiento (GPU) -> Validación -> Conversión/Compilación -> Despliegue en Producción.